MS SQL에서 특정 데이터를 조회하는 방법을 소개드립니다.
그룹별로 최상위 데이터, 최하위 데이터 혹은 행을 출력하거나
또는 테이블에서 최댓값, 최솟값을 구하고 싶을 때 사용할 수 있는 방법입니다.
예시 테이블로 부서, 입사일, 이름을 담은 EMPLOYEE 테이블을 만들었습니다.
CREATE TABLE #EMPLOYEE (
DEPT VARCHAR(50)
,START_DATE VARCHAR(50)
,NAME VARCHAR(50)
)
INSERT INTO #EMPLOYEE (DEPT, START_DATE, NAME )
VALUES
('IT팀', '2004-05-06', '여지훈')
,('회계팀', '2007-10-02', '홍길동')
,('구매팀', '2010-03-02', '찐투두')
,('IT팀', '2010-07-07', '이미영')
,('IT팀', '2012-12-02', '이기순')
,('회계팀', '2017-01-02', '김민수')
,('IT팀', '2022-08-20', '박혜민')
,('구매팀', '2022-01-06', '둘리')
,('회계팀', '2023-06-05', '한진희')▼EMPLOYEE 테이블 전체 조회 결과

1. MAX, MIN을 사용하여 최댓값과 최솟값 구하기
MAX와 MIN은 각각 특정 열(컬럼)의 최댓값과 최솟값을 구해주는 집계 함수입니다.
MAX (컬럼명) --최솟값
MIN (컬럼명) --최댓값
SELECT MIN(START_DATE) AS 최솟값, MAX(START_DATE) AS 최댓값 FROM #EMPLOYEE
2. 순위함수를 사용하여 최댓값과 최솟값 구하기
순위함수는 쿼리 결과 집합 내의 행을 각각 정의하는 함수입니다. 순위함수에는 ROW_NUMBER (), RANK() 등의 함수가 있습니다. 반드시 OVER 절을 통해 쿼리 결과 집합을 정의해주어야 합니다.
순위함수 OVER ( [PARTION BY 컬럼명 ] ORDER BY 컬럼명 ASC | DESC )
SELECT ROW_NUMBER()OVER (ORDER BY START_DATE ASC) AS No, * FROM #EMPLOYEE
3. 그룹별로 최댓값 혹은 최솟값을 가진 행 출력하는 방법
테이블에서 부서별로(그룹별로) 입사한지 가장 오래된 사람에 대한 행을 출력하고자 할 때 어떻게 할까요?
▼얻고자 하는 결과

SELECT DEPT, MIN(START_DATE), NAME
FROM #EMPLOYEE
GROUP BY DEPT위와 같이 쿼리를 작성하면 아래와 같은 메세지가 뜨며 쿼리가 실행되지 않습니다.
GROUP BY 를 쓰면 테이블의 일부 행을 대상으로 집계 함수를 사용할 수 있으며
집계함수는 특정열의 데이터끼리 연산을 수행하여 테이블을 출력합니다.
GROUP BY 한 행의 수와 특정 컬럼의 행의 수가 같아야하므로 위의 쿼리는 실행되지 않습니다.
* GROUP BY 한 행의 수: (3) / DEPT: 3 / MIN(START_DATE): 3 <-> NAME : 9

그렇다면 어떡해야 할까?
--그룹별로 가장 오래된 입사일을 가진 행
SELECT *
FROM #EMPLOYEE
WHERE START_DATE IN (SELECT MIN(START_DATE)
FROM #EMPLOYEE
GROUP BY DEPT) -- ('2010-03-02', '2007-10-02','2004-05-06')
--그룹별로 가장 최근인 입사일을 가진 행
SELECT *
FROM #EMPLOYEE
WHERE START_DATE IN (SELECT MAX (START_DATE)
FROM #EMPLOYEE
GROUP BY DEPT) --('2022-01-06','2022-08-20','2023-06-05')
ORDER BY START_DATE서브쿼리를 이용하면 부서별로 입사일이 가장 오래된 행만 가져올 수 있습니다. 행으로!!!!
같은 방법으로 부서별로 입사일이 가장 최근인 행도 가져올 수 있습니다.
▼MAX, MIN 을 통해 결과 출력
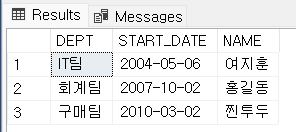

위의 방법은 서브쿼리 내에 MAX , MIN 함수를 이용하여 출력하였다면 서브쿼리 내에 순위함수를 사용하여 같은 결과값을 가져올 수 있습니다.
-- 부서별로 입사일을 기준으로 내림차순 정렬한 결과 출력
SELECT DEPT
, NAME
, START_DATE
, RANK() OVER (PARTITION BY DEPT ORDER BY START_DATE DESC) AS 입사일
FROM #EMPLOYEE순위함수를 통해 쿼리 결과 집합 내의 행을 정의해주었습니다.
OVER 절을 보면
부서별로 나눠서 (PARTITION BY ) / 입사일을 기준으로 내림차순 정렬(ORDER BY) 하여
순위를 매겨주었습니다.

위의 쿼리를 서브쿼리로 하여 얻고자 하는 결과를 출력할 수 있습니다.
--그룹별로 가장 오래된 입사일을 가진 행
SELECT *
FROM (
-- 부서별로 입사일을 기준으로 내림차순 정렬한 결과 서브쿼리로
SELECT DEPT
, NAME
, START_DATE
, RANK() OVER (PARTITION BY DEPT ORDER BY START_DATE DESC) AS 입사일
FROM #EMPLOYEE
) employee --별칭 필수
WHERE 입사일 = 1▼RANK() 순위함수를 통해 결과 출력

이런 식으로 서브쿼리를 통해 집계함수와 순위함수를 활용한다면 원하는 출력 결과를 쉽게 조회할 수 있을 것입니다.
만약 테이블에 자동 생성 시퀀스 넘버를 컬럼으로 하였다면 위의 방법을 활용하여
가장 최근에 삽입된 행(마지막으로 삽입된 데이터) 혹은 최초에 삽입된 행으로 데이터를 쉽게 찾아볼 수 있습니다.
'MS SQL' 카테고리의 다른 글
| MS SQL_REPLACE, TRANSLATE 함수로 다중 문자열 치환하는 방법 (0) | 2023.08.02 |
|---|---|
| MS SQL_ UNPIVOT 사용하는 방법 (0) | 2023.04.28 |
| MS SQL_SQL 계정의 암호가 만료되었습니다. (0) | 2023.03.06 |
| MS SQL 대소문자 변환 및 대소문자 구분 검색 (0) | 2023.01.27 |
| MS SQL_IF EXIST문 사용법 (0) | 2022.10.26 |


